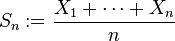I am currently working on setting up the work environment for
Facebook App development on
Heroku server using
python as the development language.
The complete tutorial is at:
https://devcenter.heroku.com/articles/facebook
On high level the steps involve:
- Creating a new facebook app and checking the option for Heroku hosting.
- This creates a new domain on Heroku for your app and installs your app there.
- Now, you can 'git clone' the code on your local machine, make changes to the code and 'git push heroku master' to push changes back to the world.
- Need to setup the local environment for testing:
- This involves setting up the virtualenv for python. http://www.virtualenv.org/en/latest/
virtualenv is a tool to create isolated Python environments. The basic problem being addressed is one of dependencies and versions, and indirectly permissions. Imagine you have an application that needs version 1 of LibFoo, but another application requires version 2. How can you use both these applications? If you install everything into /usr/lib/python2.7/site-packages (or whatever your platform’s standard location is), it’s easy to end up in a situation where you unintentionally upgrade an application that shouldn’t be upgraded.
Or more generally, what if you want to install an application and leave it be? If an application works, any change in its libraries or the versions of those libraries can break the application. Also, what if you can’t install packages into the global site-packages directory? For instance, on a shared host.
In all these cases, virtualenv can help you. It creates an environment that has its own installation directories, that doesn’t share libraries with other virtualenv environments (and optionally doesn’t access the globally installed libraries either).
Now locally test your changes before deploying on the server.
Next steps:
- To be able to use a DB backend.
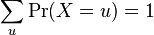
![\Pr[a\le X\le b] = \int_a^b f(x) \, dx](http://upload.wikimedia.org/math/d/7/1/d715cf83d8a655fdfc1d3a90433cd62c.png)



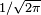 in this expression ensures that the total area under the curve ϕ(x) is equal to one
in this expression ensures that the total area under the curve ϕ(x) is equal to one ; and has
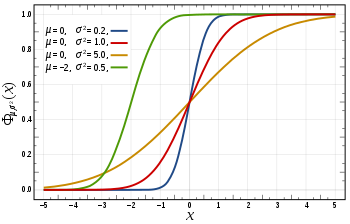
; and has ![[-\infty, x]](http://upload.wikimedia.org/math/f/e/a/fea1695aef424e4676dafd2ddad0445d.png) , as a function of x. The CDF of the standard normal distribution, usually denoted with the capital Greek letter
, as a function of x. The CDF of the standard normal distribution, usually denoted with the capital Greek letter 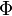 (
(